LoRAをGoogle Colabで簡単に作りたい! ただ、現状、Google Colabを使ってGUI(マウス操作)だ…

事前に必要なもの・いれといたほうがいいもの
・Python 3.10系
・Git
・Visual Studio
Kohyaのインストール手順
> ls
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2024/01/10 14:04 StableDiffusionWebUIgit clone https://github.com/bmaltais/kohya_ss
cd .\kohya_ss\
> python --version
Python 3.10.6- pyenvでPython 3.10.9を使うのはどうしたらいい?
- Kohyaのフォルダー内で行います。
pyenv install 3.10.9 # 少し時間がかかります pyenv local 3.10.9これで、Pythonのバージョンが変わっていたら問題ないです。
> python --version Python 3.10.9これでバージョンが切り替わらない場合、こちらの記事(https://teratail.com/questions/323659)を参照してみてください。
次にKohyaのセットアップを行います。
.\setup.bat※もし、Creating venv…だけで実行が終了してしまった場合、再度「.\setup.bat」を実行してください。
Enter your choceでは「1」を選択します。
Kohya_ss GUI setup menu:
1. Install kohya_ss gui
2. (Optional) Install cudann files (avoid unless you really need it)
3. (Optional) Install specific bitsandbytes versions
4. (Optional) Manually configure accelerate
5. (Optional) Start Kohya_ss GUI in browser
6. Quit
Enter your choice: 1かなり時間がかかりますが待ちます。処理が完了したら、次に、Enter your choceで「5」を選択します。
Kohya_ss GUI setup menu:
1. Install kohya_ss gui
2. (Optional) Install cudann files (avoid unless you really need it)
3. (Optional) Install specific bitsandbytes versions
4. (Optional) Manually configure accelerate
5. (Optional) Start Kohya_ss GUI in browser
6. Quit
Enter your choice: 5するとKohyaのGUIの画面が立ち上がります。
自作LoRAの作成手順
さっそくKohyaを使っていきたいところですが、まずはLoRA学習用のデータを用意する必要があります。
- Stable Diffusionで学習用データを用意する
- KohyaでLoRAを作成する
Stable Diffusionで学習用データを用意する
必要なStable Diffusionの拡張機能は2つです。
Stable Diffusioinの拡張機能の導入方法はわかりやすく画像付きで解説しているので「Stable Diffusionの拡張機能のインストール/停止/削除/アップデート方法」をチェックしてください。
また、Kohyaの中にoutputs、training、training_archive、というフォルダーを作っておきます。
| outputs | 作成したLoRAの格納場所 |
| training | LoRA学習用の画像格納場所 |
| training_archive | 過去にLoRA学習した画像の格納場所(2回目以降必要になります) |
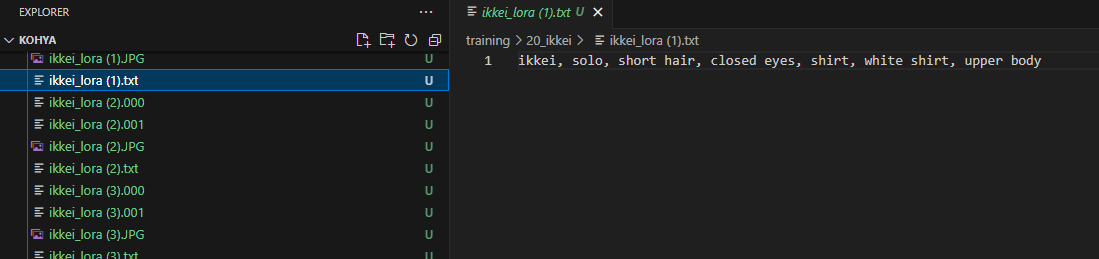
trainingフォルダーの中に、さらにフォルダーを作ります。
ここで注意なのが、[学習の繰り返し回数]_[トリガープロンプト]という名前付けをする必要があり、なんでもつけていいわけではありません。
また、このトリガープロンプトは今後も使うので決め切っておいてください。今回は、20_ikkeiというフォルダーを作り、その中に学習させる画像を格納していきます。
- どんな画像を用意すればいい?画像の条件と最適枚数
- 画像選定では、ここらへんを最低限守りましょう。
・クオリティが低いものはいれない
・顔全体が映っている(顔を学習させたい場合)
・横顔や笑顔などが含まれている(顔を学習させたい場合)
学習させる画像の枚数は、20~30枚くらいでOKです。
画像のサイズ・縦横比はバラバラでOKです。
- 画像の名前が連番になっていない場合
- Windowsでは一括で名前変更をすることでファイル名を連番にすることができます。
まずWindowsエクスプローラーで今回学習する画像を一括選択してください。

一括変更したそのまま、右クリックをして、その他のオプションを確認をクリックします。

名前の変更をクリックします。

なんでもいいので名前を付けてください。一応名前はアルファベットを使用するようにしましょう。

完成です!

Tagger
Taggerは画像からそれぞれプロンプトを抽出してテキストファイルにまとめてくれる拡張機能です。
TaggerをStable Diffusioinにインストール出来たら、先ほど学習画像を格納したフォルダーのパスをコピーしてきてください。
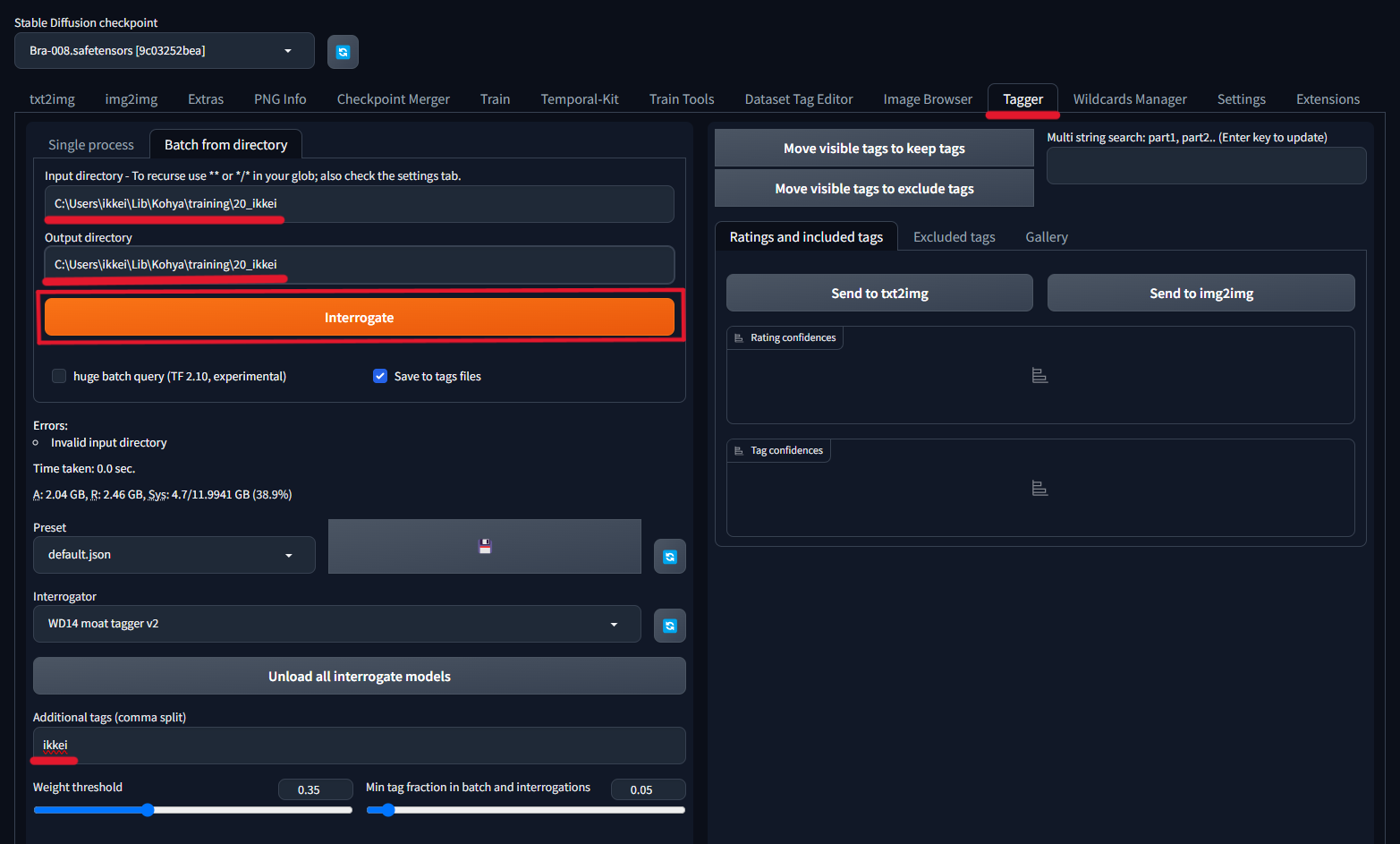
| Input directory | 学習画像を格納したフォルダー |
| Output directory | 学習画像を格納したフォルダー |
| Additional tags (comma split) | トリガープロンプト |
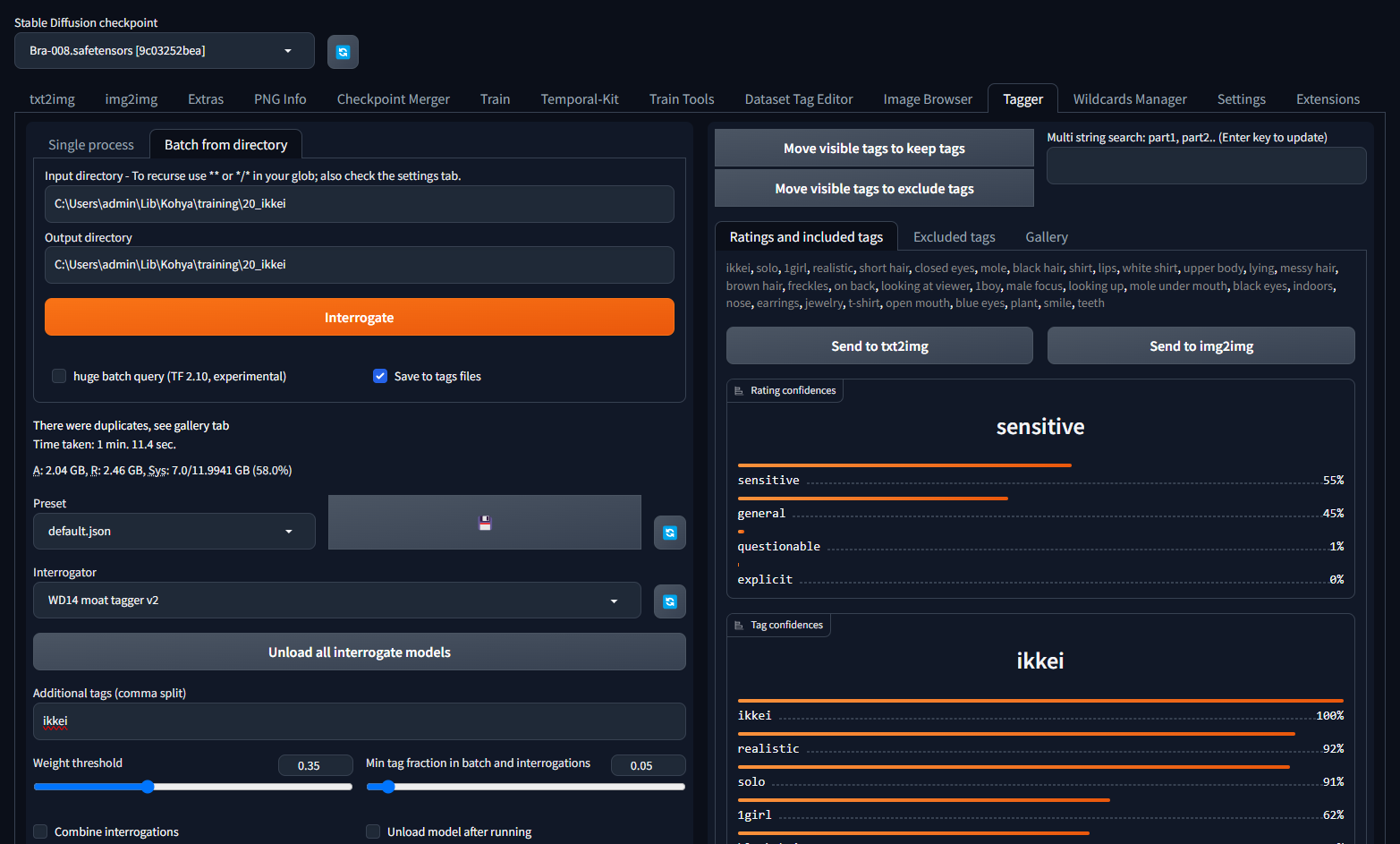
Interrogateをクリックしてしばらく待ちます。
実行が完了したら以下のような画面になります。これでTaggerの工程は完了です!
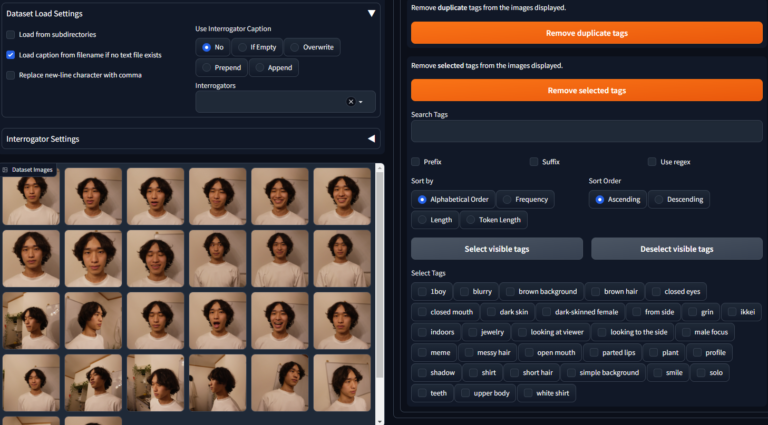
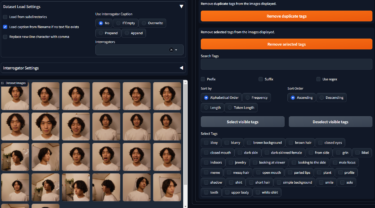
Dataset Tag Editor
Taggerで抽出したプロンプトを手動で修正します。
まずは、画像を読み込むため、Dataset directoryにTaggerの時と同じく学習画像を格納したフォルダーを入れて、Loadをクリックします。
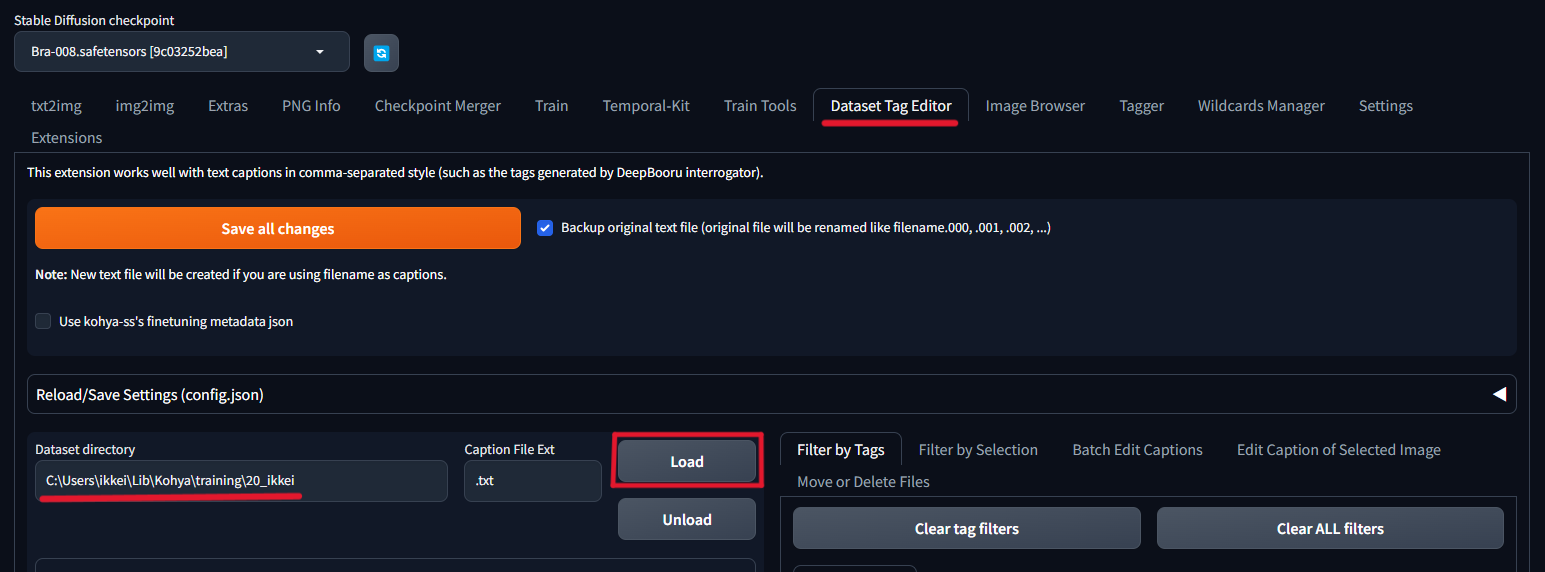
画像の読み込みが終わったら、次はプロンプトの一括編集を行います。
Batch Edit Captions > Removeから学習してほしいタグにチェックをつけて、Remove selected tagsをクリックします。(え?学習するほうを削除するの?と思わたと思うので下で解説します)
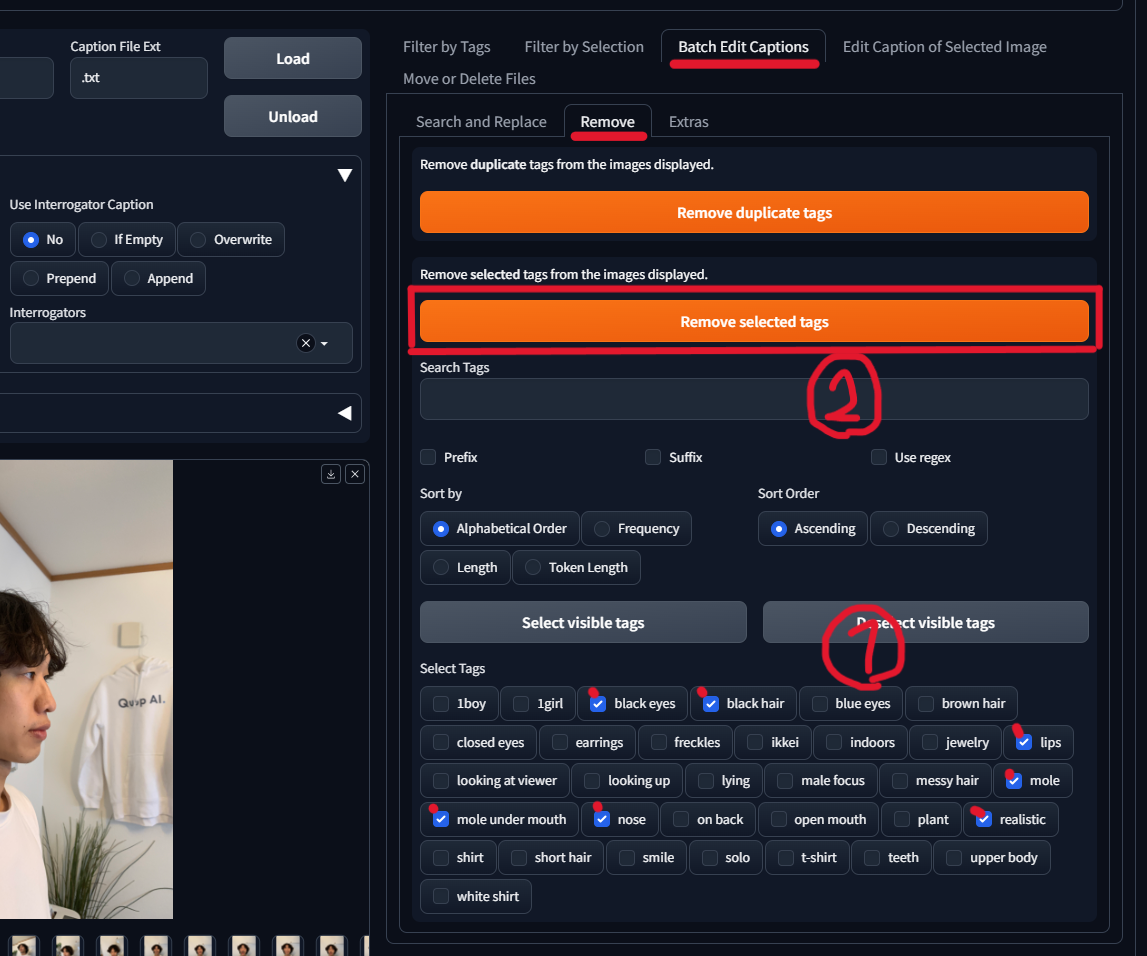
・的外れなプロンプト(今回だと、男なのに「1girl」とか)
・トリガープロンプト(今回はikkei)
最後に、Save all changesをクリックするのをお忘れなく!
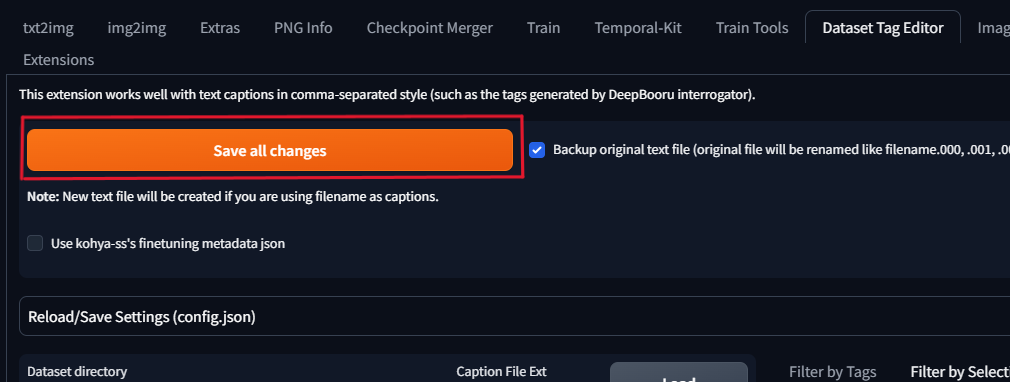
(押しても変化がないように見えますが、画像フォルダーの中身のtxtファイルからタグが削除されてたらOKです)
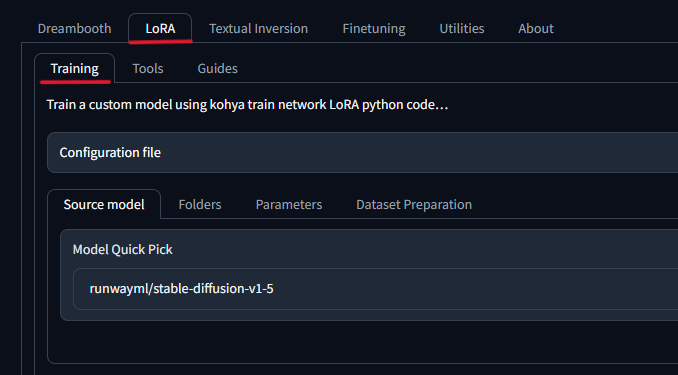
KohyaでLoRAを作成する
いよいよKohyaを使って自作LoRAを作っていきます。Kohyaの画面に戻ってくださいね!GUIの画面は立ち上がったままでしょうか?
- Lore > Training > Source model
- Lore > Training > Folders
- Lore > Training > Parameters > Basic
- Lore > Training > Parameters > Advance
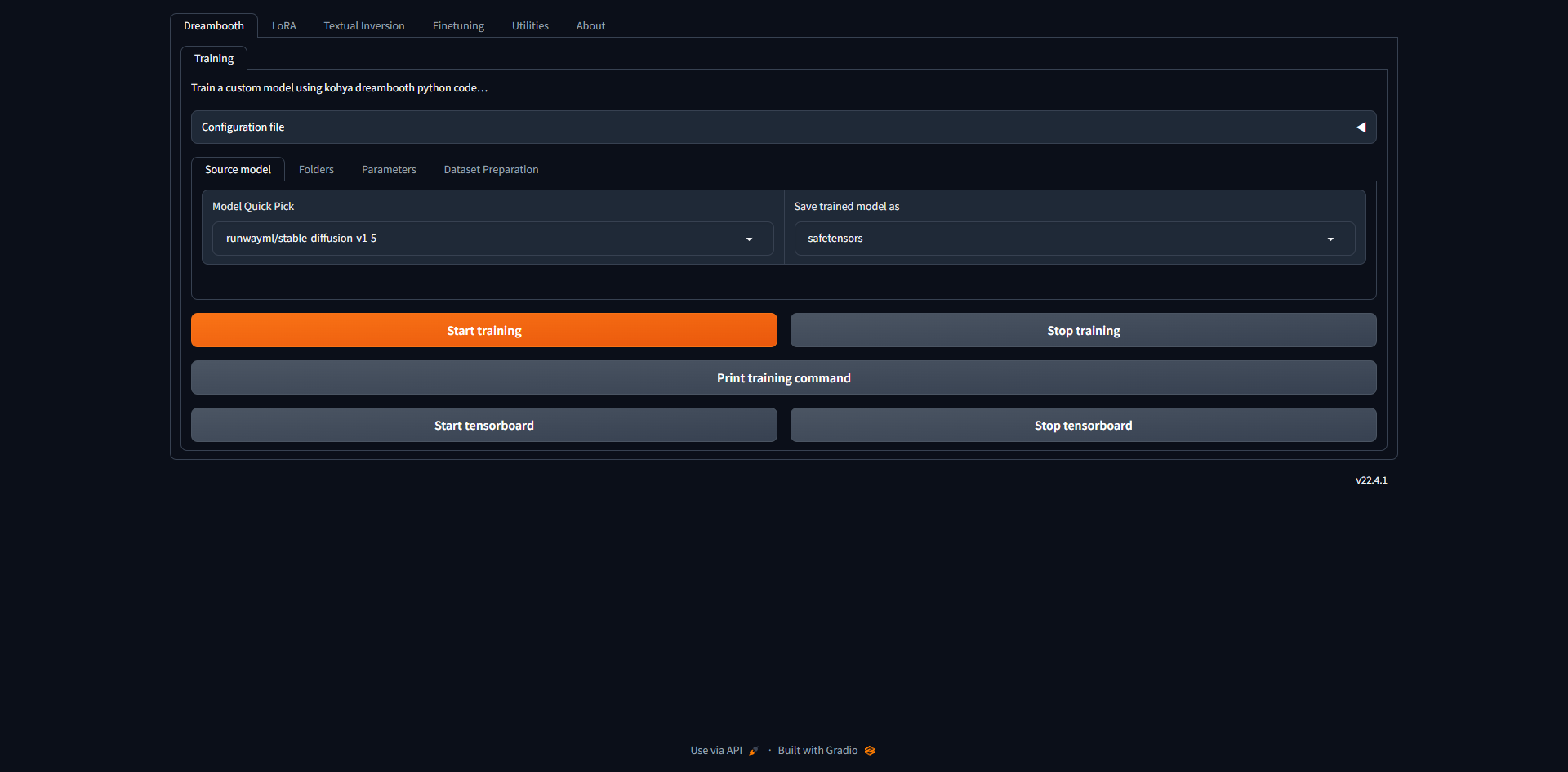
Lore > Training > Source model
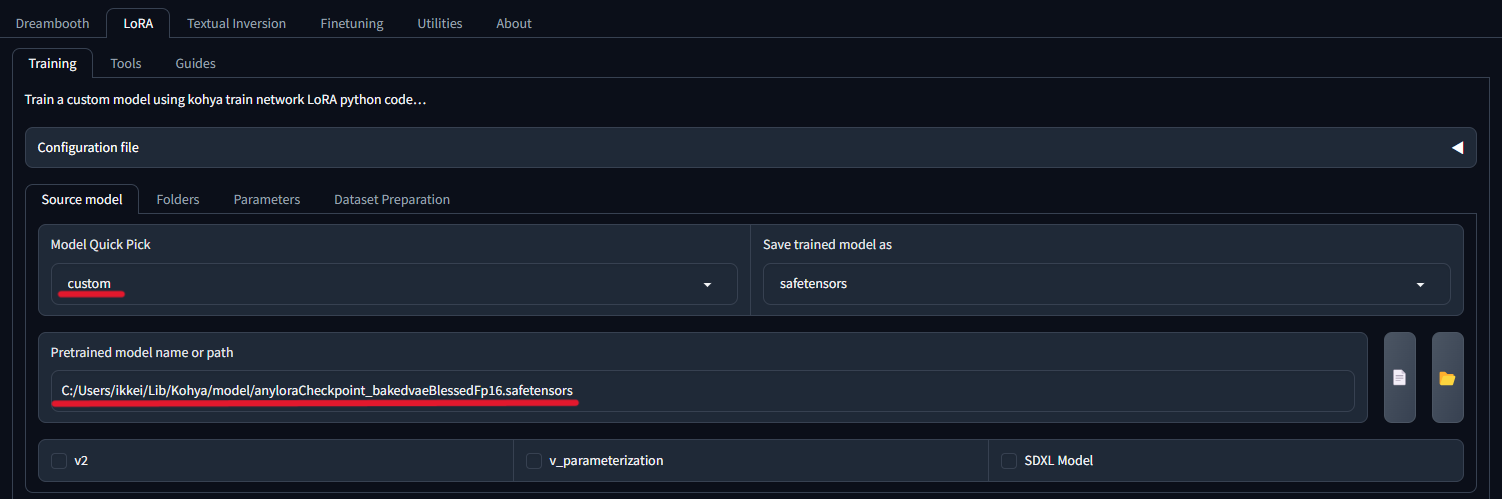
ここは、実写・リアル系であればデフォルトの設定のままで大丈夫です。
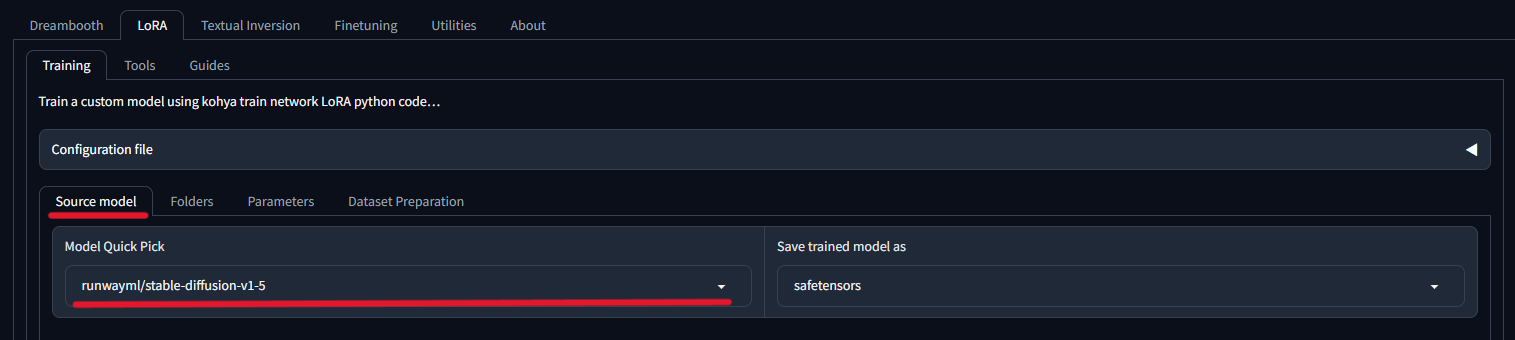
- アニメ系の画像を学習させたい場合
-
アニメ系の場合は、AnyLoRA(リンクに飛びます)をダウンロードする必要があります。Model Quick Pickでcustomを選択して、Pretrained model name or pathでダウンロードしたsafetensorsファイルのパスを指定してください。safetensorsファイルの格納場所はどこでも大丈夫ですが、Kohyaの中に作ったtrainingフォルダーなどと並べてmodelというフォルダーを作り、そこに入れておくのがいいでしょう。


Lore > Training > Folders
まず、前に作ったKohyaのoutputsフォルダーに、新しく[学習の繰り返し回数]_[トリガープロンプト](今回だと20_ikkei)という名前のフォルダーを作ります。
あとは、以下の画面のように3箇所入力してください。
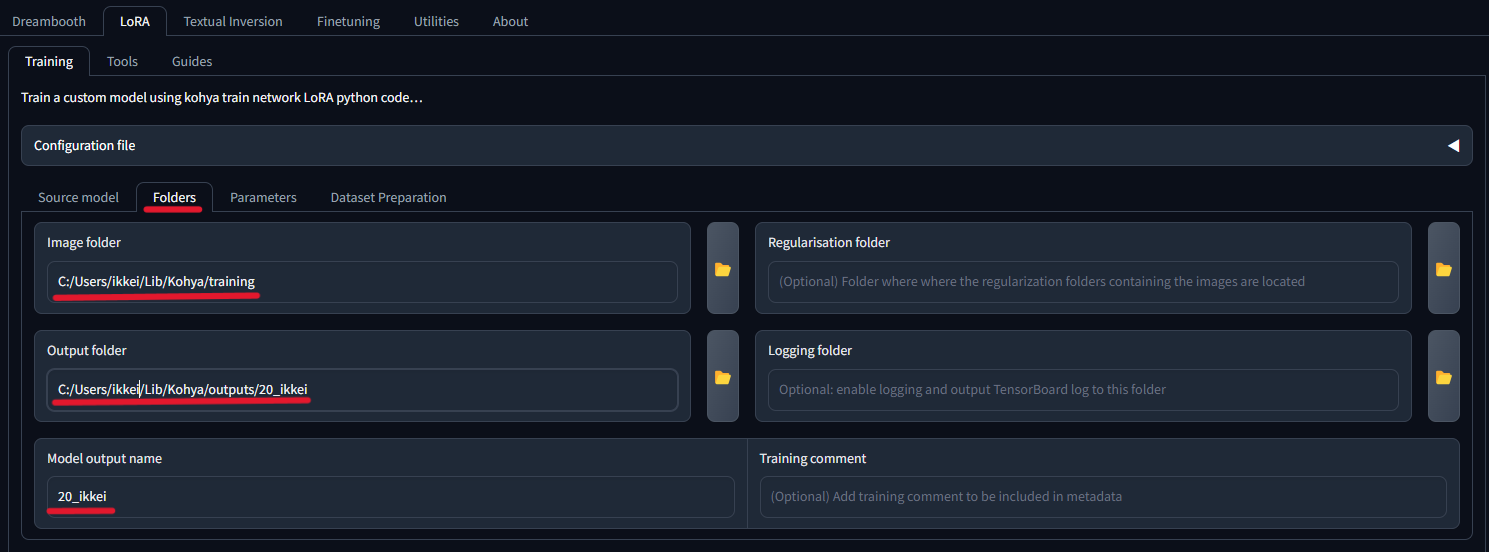
| Image folder | 学習画像を格納したフォルダーの親フォルダー(= trainingフォルダー) |
| Output folder | 今作ったoutputs内のフォルダー |
| Model output name | [学習の繰り返し回数]_[トリガープロンプト] |
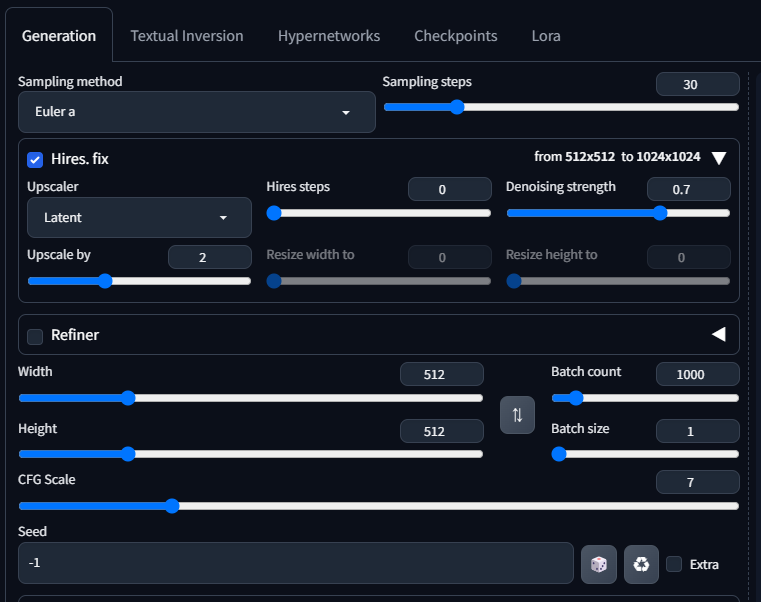
Lore > Training > Parameters > Basic
このParametersの設定がLoRAのクオリティに影響します。
とりあえず、色々検証した結果、以下の設定が最適でした。
もっと知りたい方向けにあとで少し設定について解説します。
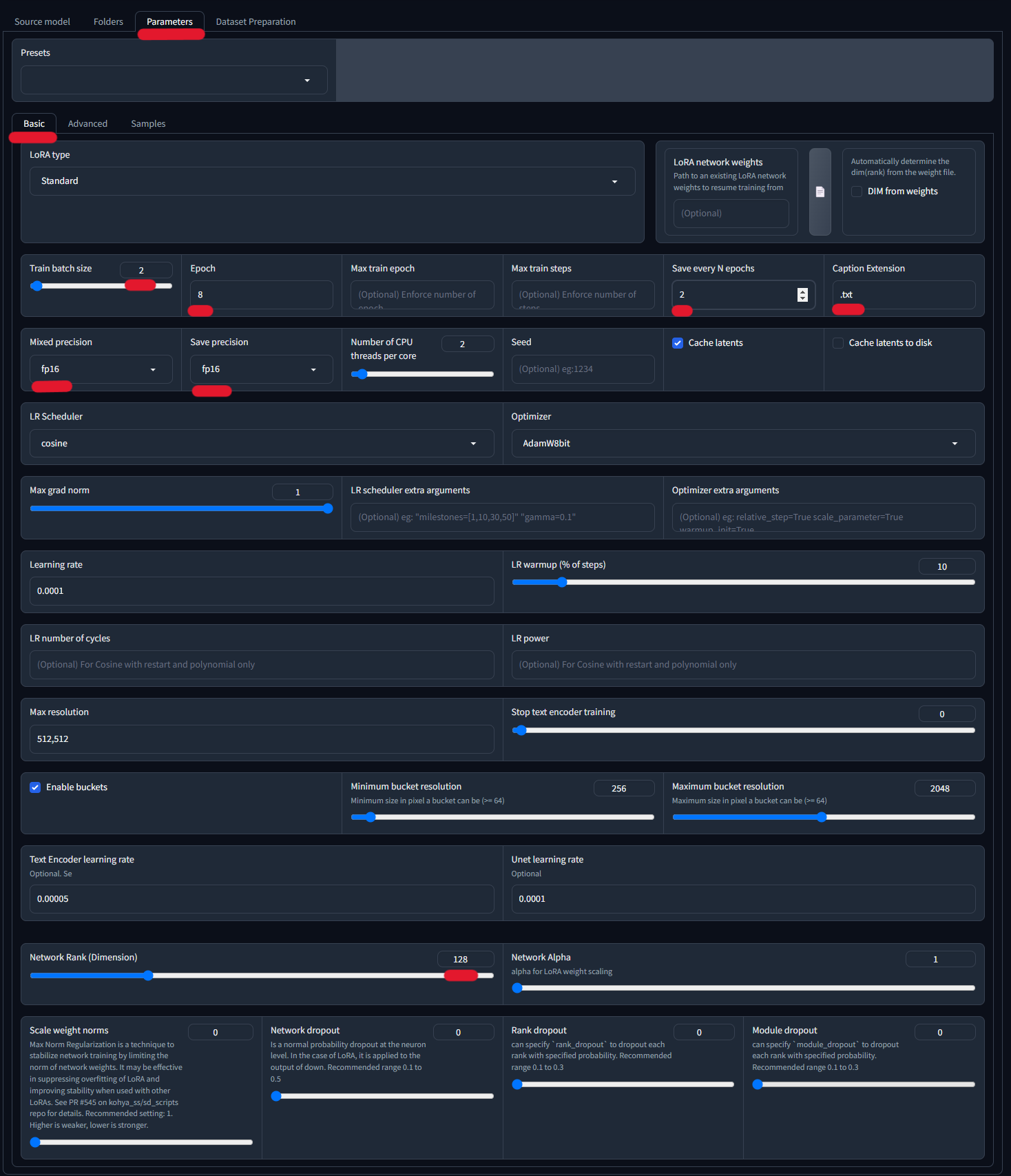
| Train batch size | 一度に処理されるデータポイントの数です。小さなバッチサイズはメモリ効率が高く、大きなバッチサイズはトレーニング速度が速い傾向があります。設定値:2 |
| Epoch | エポック数はトレーニングの繰り返し回数を表します。設定値:8 |
| Save every N epochs | モデルのトレーニング中にモデルのチェックポイントを保存する頻度を指定します。細かく設定することで最適なエポック数のモデルが分かります。設定値:2 |
| Caption Extension | キャプションファイルの拡張子を指定します。設定値:.txt |
| Mixed precision/Save precision | モデルの浮動小数点精度の設定を指します。設定値:fp16 |
| Network Rank (Dimension) | モデルのネットワーク構造の次元数を指します。次元数はモデルの複雑さを示します。設定値:128 |
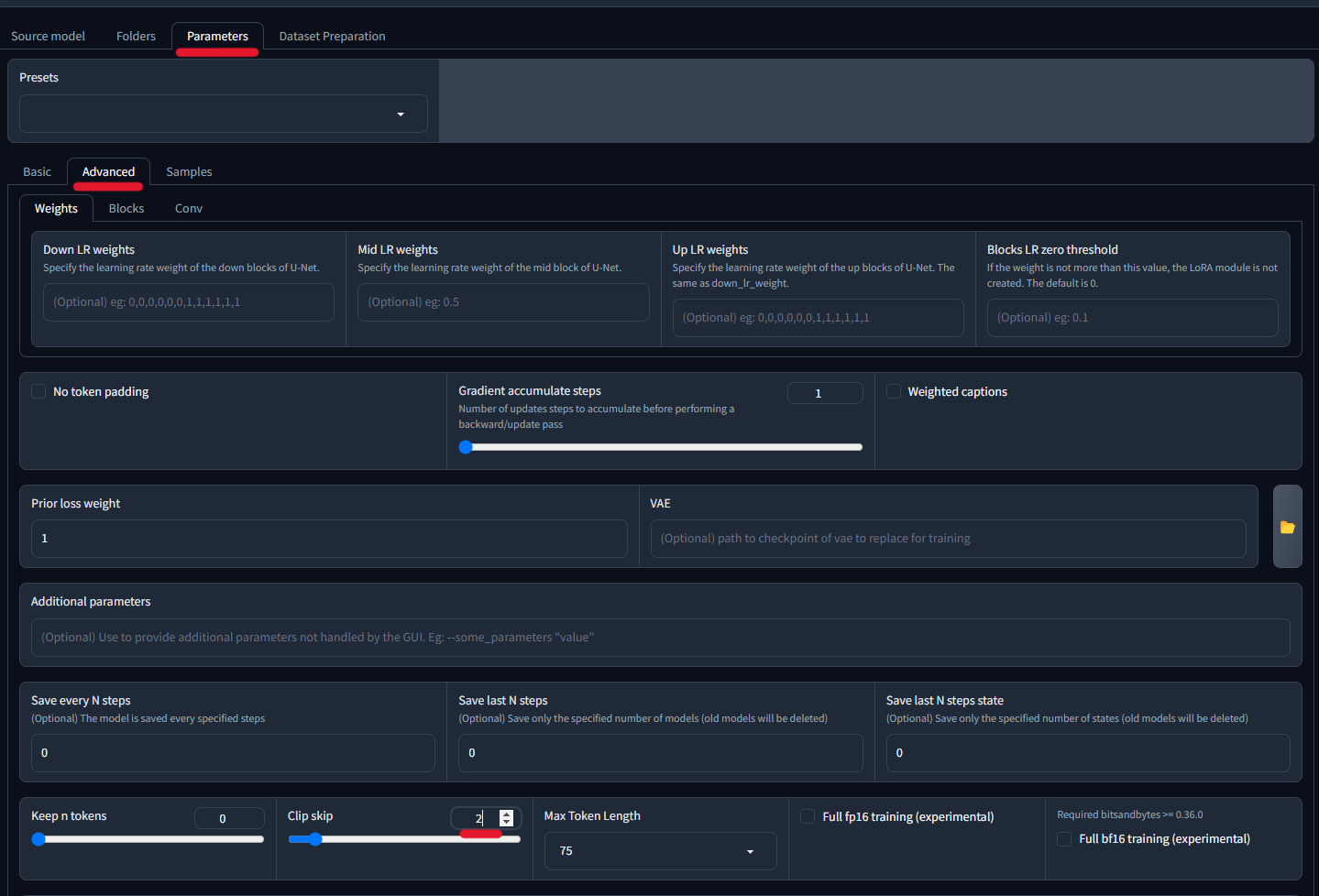
Lore > Training > Parameters > Advance
ここでは、Clip skipを2に設定するだけでOKです。
トレーニング開始
- 「ImportError: No bitsandbytes / bitsandbytesがインストールされていないようです」の対処法
- Kohyaをインストールしたフォルダーで以下を実行してください。(Kohyaのセットアップで使ったsetup.batがある階層と同じところです)
.\venv\Scripts\pip.exe uninstall bitsandbytes .\venv\Scripts\pip.exe install bitsandbytes-windows
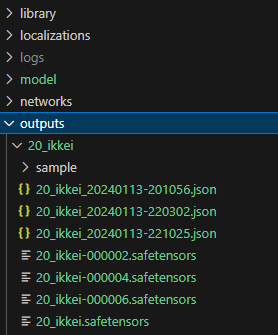
しばらくするとoutputsフォルダーの中にsafetensorsファイルが格納されます。これが僕のLoRAです!
自作LoRAを使って画像生成をする
ではこのLoRAを使って、Stable Diffusionで画像を生成をしてみます。
とりあえず、20_ikkei.safetensorsを使います。
modelにはBra v7を使用しました。(リアル系のアジア人が得意なモデルですね)
prompt
Zuri from USA, long frizzy [blue-black:.3] hair, (masterpiece,best quality:1.4),(8k,raw photo,photo realistic:1.2), realistic, 1man, single-fold eyelid, 1boy, asian, front, looking at view, short hair, <lora:20_ikkei:1>Negative Prompt
painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured, photo, deformed, black and white, realism, disfigured, low contrast, painting, stripes, sketches, monochrome, grayscale, text, watermark, title, (low quality, lowres, worst quality, medium normal quality:1.4), (bad anatomy:1.8), poorly drawn face, , 0001SoftRealisticNegativeV8-neg, (UnrealisticDream:1.2), animal ears, bad-hands-5, bad-picture-chill-75v, bad_pictures, BadDream, badIrisNegあとの設定はこんな感じです。
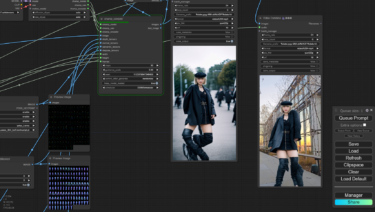
そして、これが実際の僕(ikkei)です。

さて、この僕の画像とどれくらい似ている画像ができるのか…画像生成をスタートしてみましょう…。
1000枚でバッチ処理して放置します。
約3時間後…
できました!

ちょっと目元の雰囲気がもとのBraモデルに影響されていますが、眉毛・鼻・口・髪型はかなり精度がいいのではないでしょうか?
プロンプトで、涙袋を消して、もっと一重にしたらまんま僕ですね。LoRAを使っていてもプロンプトは大事です。
横顔はこんなかんじ。ちょっとまだ学習が足りていない感じですね。イケメン度が強すぎる気がします。


ここからさらにプロンプトを調整して、より僕に近づけていきます。
プロンプトで一重を強調したり、ネガティブプロンプトで顔に関するものを削除しました。
Prompt
Zuri from USA, long frizzy [blue-black:.3] hair, (masterpiece,best quality:1.4),(8k,raw photo,photo realistic:1.2), realistic, realistic skin, detailed skin:1.2, 1man, slant eyes:1.5,single eyelids:1.2, monolid:1.2, 1boy, asian:1.2, asian man, japanese, front, looking at view, short hair, <lora:20_ikkei>Negative Prompt
tear bag:1.5, dark circles:1.2, bags:1.5, Beard, painting, bad-image-v2-39000




このようにクオリティが高くなるLoraの使い方だったり、アニメ系・実写系それぞれのおすすめの設定や、効率の良い検証方法は別でまとめますので乞うご期待です。

 オリジナルAIのビジネス利用なら「Quup AI」" width="1280" height="1067" src="https://ai-island-media.com/wp-content/themes/the-thor/img/dummy.gif">
オリジナルAIのビジネス利用なら「Quup AI」" width="1280" height="1067" src="https://ai-island-media.com/wp-content/themes/the-thor/img/dummy.gif">