


画像のキャラクターを動かす系で今流行っているのがchampです。
champはオープンソースなため、無料で利用することができます。
MagicAnimate、Animate Anyone、AnimateDiffなどをベースに作られているようです。
champは何ができる?
こんな風に画像を動かすことができます!Magic Animateよりも自然な動画が生成されていますね。
また、DemoAIのように顔が変わりにくいのも特徴です。(DemoAIを含めたダンス系のAIを比較している記事はこちら)
なにより、champは様々なカスタマイズが可能で、実運用でもしっかり使えるのが良いところです。
- 画像動かす系AIの中でクオリティ最上級
- 動画の雰囲気(モデル)の変更や背景、パラメータの調整などのカスタマイズが可能
- 無料で利用できる
champを極めたら最強です!
【プロ版】上級者向け、だがおすすめ!ComfyUIでchampを使い倒す
※2024年4月8日追記
champではGUI(マウス操作できる画面)が用意されていないため、カスタマイズするためにはファイルをごちゃごちゃいじる必要があります。
それは、ちょっとめんどくさいですよね?
そこで、ComfyUIを使うことで、メモリ(VRAM)の消費を抑えながら、マウス操作でよりクオリティの高い動画を生成することができます。
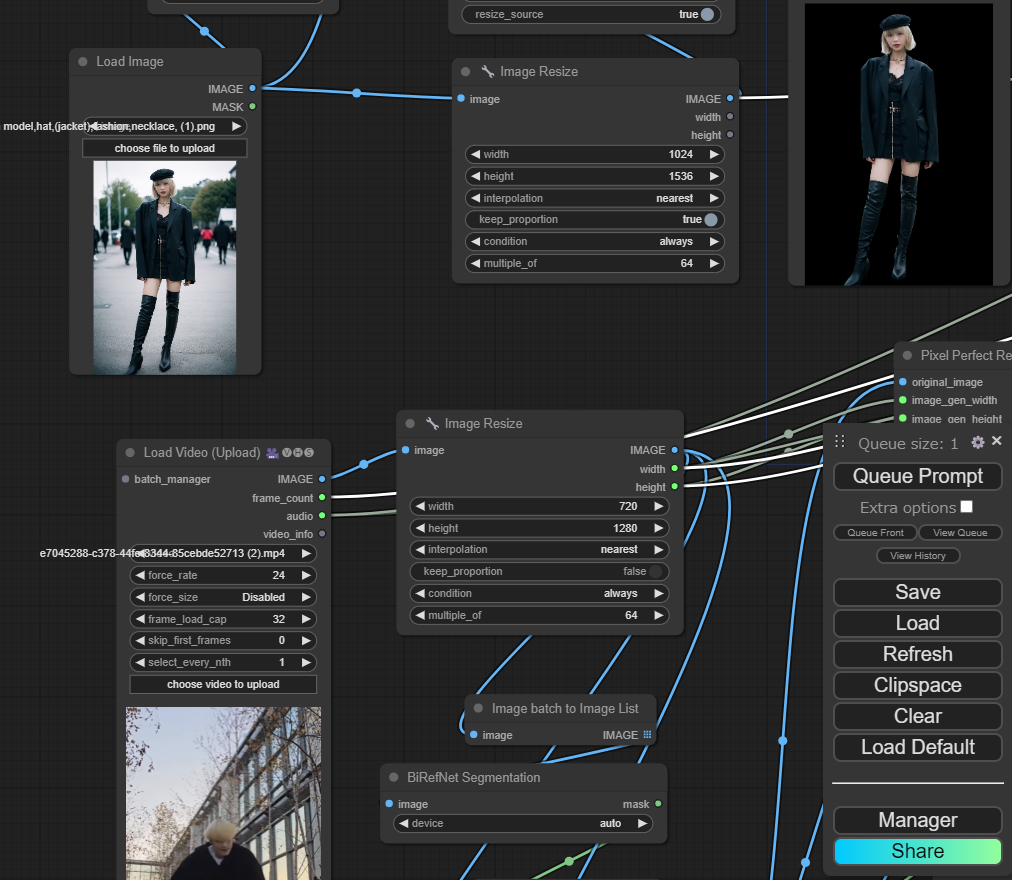
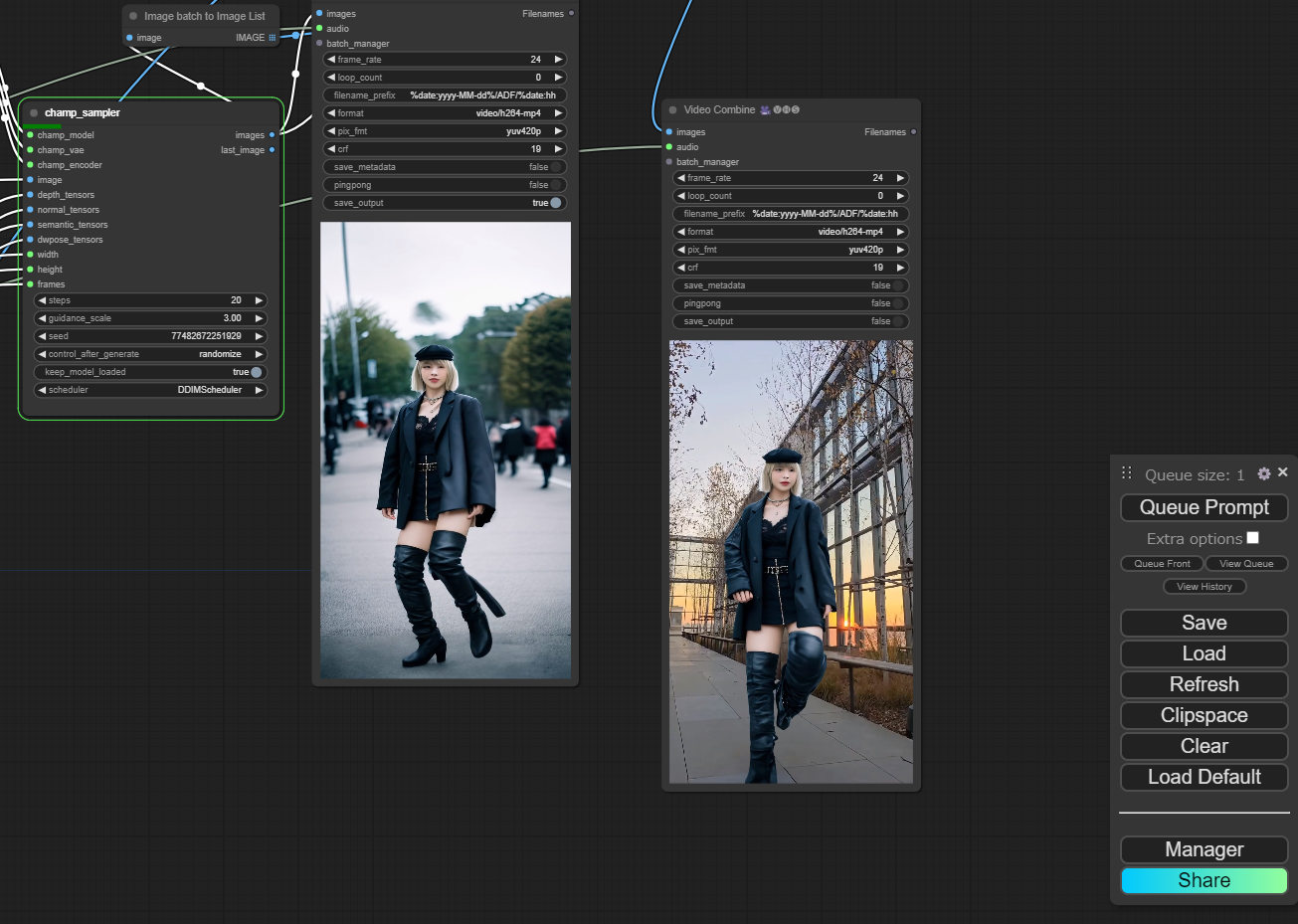
もちろん、テンプレ用意済み!
GUI(マウス操作できる画面)で誰でもカンタンに画像キャラクターをダンスさせることが可能です!
この記事では「champ」を使った画像を動かす方法について、徹底解説しています。 ダンスAIが流行っていますが、意外と…

【デモ版】とりあえず試してみたい初心者向け!
まずは、難しいことはやりたくない…簡単な方法教えて…という方向けの方法です。
クオリティ高いものを試してみたい方は以下のComfyUIを使った方法をおすすめします。
この記事では「champ」を使った画像を動かす方法について、徹底解説しています。 ダンスAIが流行っていますが、意外と…
Google Colab
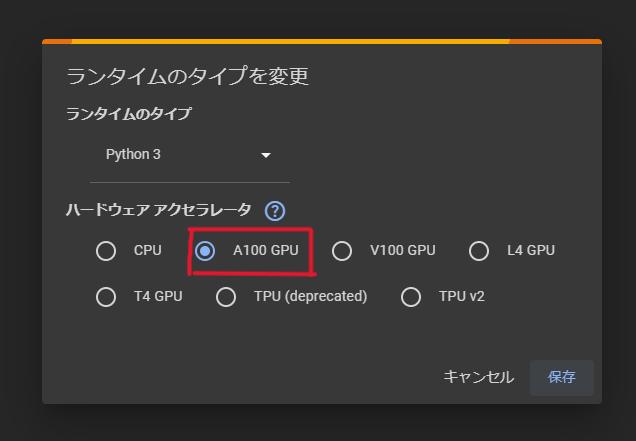
まずは、こちらのGoogle Colabのリンクにアクセスしてください。
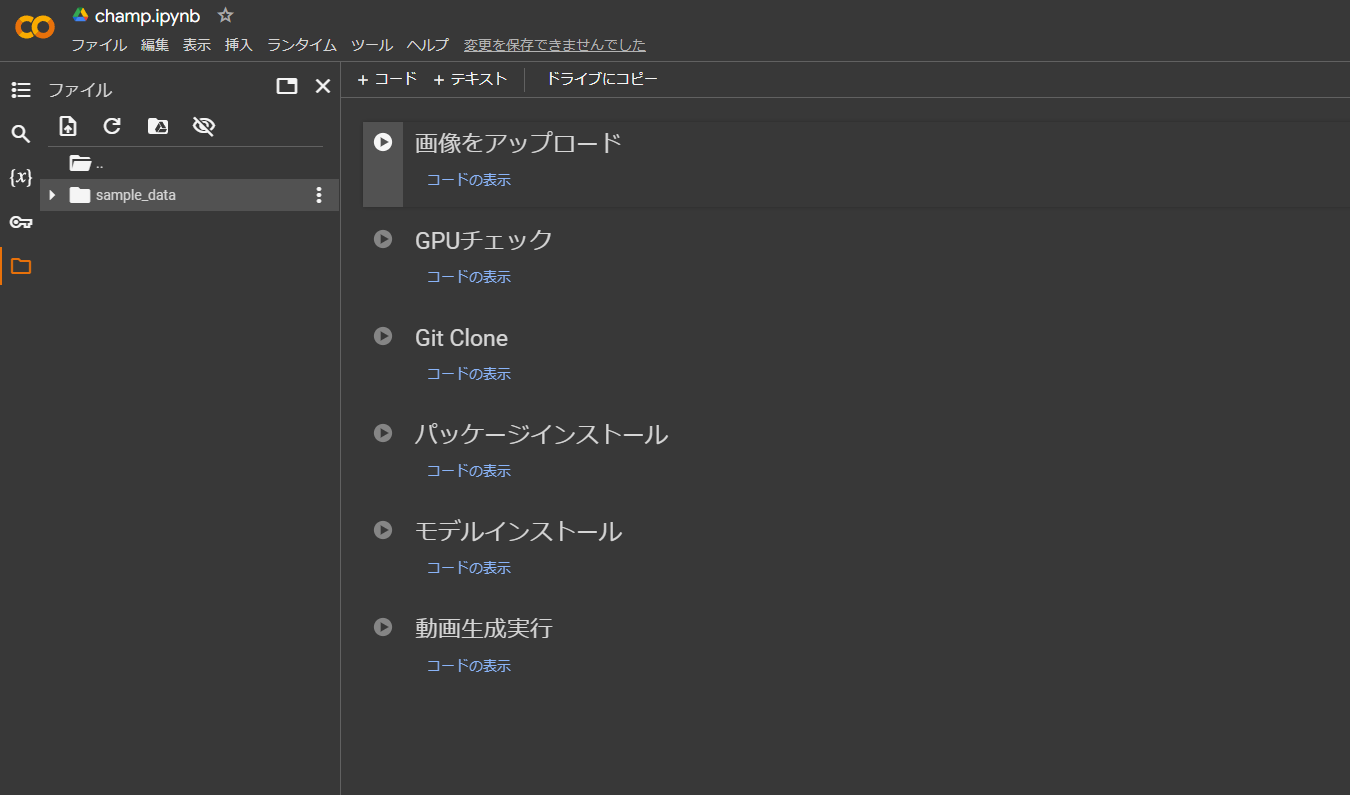
champ > resultsに生成された動画が日付順で入っています。
その中で、animation.mp4が生成された動画そのものです!
Windowsにローカルで建てる
ローカルだとハイスペックなグラフィックボードが必要です。以下の環境以上でなければ難しいでしょう。(私のWindows PCはNVIDIA GeForece RTX 4060を積んでいますが、動画生成に12時間くらいかかりました)
推奨されている(検証済み)スペックは以下の通りです。逆にこれより低ければGoogle Colabを利用しましょう。
- System requirement: Ubuntu20.04/Windows 11, Cuda 12.1
- Tested GPUs: A100, RTX3090
まずは任意のディレクトリで以下のようにソースコードをダウンロードします。
git clone https://github.com/fudan-generative-vision/champ.git
cd champcondaを使って仮想環境をつくります。(普段venvを使っている方もcondaを使ってください)
ここで、conda activateをしても仮想環境が切り替わらない場合はこちらの記事を参考にしてみてください。
conda create -n champ python=3.10
conda activate champ
Windowsユーザーはpoetryを使うことが推奨されているみたいです。poetryを使って必要なパッケージをインストールします。(pipの工程は不要です)
poetry install --no-rootモデルを入れる用のpretrained_models/フォルダーを作成します。
mkdir pretrained_models
cd pretrained_modelsまず、pretrained_models/の中にimage_encoder/ディレクトリを作成します。
mkdir image_encoderこのimage_encoder/に対してこちらのページにあるconfig.jsonとpytorch_model.binをダウンロードして入れます。
さらに、モデルのダウンロードをしていきます。(これにはとんでもなく時間がかかるので辛抱強く待ちましょう。僕は1時間以上かかった気がします)
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
git clone https://huggingface.co/stabilityai/sd-vae-ft-mse
git clone https://huggingface.co/fudan-generative-ai/champここで、pretrained_models/champ/example_data.zipを解凍します。プロジェクトのルートディレクトリにexample_data/がある形ですね。(pretrained_models/の隣)
全体の構成はこんなかんじ。
./example_data/
./pretrained_models/
|-- champ
| |-- denoising_unet.pth
| |-- guidance_encoder_depth.pth
| |-- guidance_encoder_dwpose.pth
| |-- guidance_encoder_normal.pth
| |-- guidance_encoder_semantic_map.pth
| |-- reference_unet.pth
| `-- motion_module.pth
|-- image_encoder
| |-- config.json
| `-- pytorch_model.bin
|-- sd-vae-ft-mse
| |-- config.json
| |-- diffusion_pytorch_model.bin
| `-- diffusion_pytorch_model.safetensors
`-- stable-diffusion-v1-5
|-- feature_extractor
| `-- preprocessor_config.json
|-- model_index.json
|-- unet
| |-- config.json
| `-- diffusion_pytorch_model.bin
`-- v1-inference.yamlあとは以下のコマンドを実行するだけ!
poetry run python inference.py --config configs/inference.yamlconfigs/inference.yamlを編集することで、なんの画像を使うかなどを指定することができます。